每天进步多一点,妈妈夸我小天才~(雾)
感谢在我前进道路上为我指点迷津的各位师傅(鞠躬)
对我来讲,学汇编学pwn真的不是个容易活……只能加油,加油,加加油了!!
第一天
有亿点累的一天orz(其实用了三天来学这些东西)
前置知识
CPU对存储器的读写
CPU要想进行数据的读写,必须和外部器件(即芯片)进行三类信息的交互:
1.地址信息:存储单元的地址 2.控制信息:芯片的选择,读或写命令 3.数据信息:读或写的数据
CPU=运算器+控制器+【寄存器】,器件之间通过总线相连
一个16位寄存器所能存储的数据的最大值为多少?
因为每一位存放的数据是0或1,那么最大的数值自然就是 1111 1111 1111 1111(2),也就是2^16-1
汇编指令是不区分大小写的
mov AX,BX 的意思是将BX中的数据放在AX中
add AX,BX 的意思是将BX与AX相加,放在AX中
如果超过数据的存储范围,就会有数据的丢失
这里的丢失,指的就是进位制不能在8位寄存器中保存,但是CPU不是真的丢弃这个进位值。
CPU访问内存单元时要给出内存单元的地址,所有的内存单元构成的存储空间是一个一维的线性空间。
我们将这个唯一的地址称为物理地址。
关于段空间
内存没有分段,段的划分来自于CPU,
由于8086CPU用“(段地址×16)+偏移地址=物理地址”的方式给出内存单元的物理地址,
使得我们可以用分段的方式来管理内存。
何为寄存器?
看了点资料,还是有点迷,于是打开知乎发现一条匿名用户的解答
寄存器就是你的口袋。身上只有那么几个,只装最常用或者马上要用的东西。
内存就是你的背包。有时候拿点什么放到口袋里,有时候从口袋里拿出点东西放在背包里。
辅存就是你家里的抽屉。可以放很多东西,但存取不方便。
还有一个回答我也很喜欢
如果把被储存的东西比作能量:
寄存器就是 ATP,可以随时拿来用,性能高,但数量有限;
内存就是葡萄糖,性能一般,但是存量可以比较多;
外存(比如硬盘)就是脂肪,容量可以非常大,性能很差,要先转化为葡萄糖(存进内存),然后转化为 ATP(放到寄存器)才能直接利用(存取)。
了解完什么是寄存器之后再来见一见常见的寄存器有哪些
几个常用的寄存器
首先,e开头的为x32,r开头的为x64。
寄存器有多种用途,但每一个都有“专长”,有各自的特别之处
数据寄存器:AX、BX、CX、DX
一般寄存器:AX、BX、CX、DX
AX:累积暂存器,BX:基底暂存器,CX:计数暂存器,DX:资料暂存器
一个寄存器可以存放16bit,也就是2bytes. 所以也被称为16位寄存器
1GB=1024MB=1024*1024KB
1KB=1024Byte(字节) 1Byte=8bit(比特)
那它们有什么特殊的地方使得它们和其他寄存器不一样呢? 那是因为这四个16位寄存器可以被分为两个8位寄存器,比如
AX = AH + AL, BX = BH+BL, CX = CH + CL, DX = DH+DL
AH是AX的高字节(高8位),AL是AX的低字节(低8位)
其余三个同理
一个16位寄存器所能存储的数据的最大值为多少?
因为每一位存放的数据是0或1,那么最大的数值就是 1111 1111 1111 1111(2),也就是2^16-1
变址寄存器:SI、DI
SI:源变址寄存器,DI:目的变址寄存器
SI DI不能够分成两个8位寄存器来使用,二者都是在某个地址的基础上进行偏移变化所以叫基址暂存器。
这两个寄存器有自动增量和自动减量的功能所以用于变址是很方便的。
指针寄存器:SP、BP
SP:堆栈指针暂存器,BP:基底指针暂存器
先说BP,基底指针暂存器其内存放着一个指针,该指针永远指向系统栈最上面一个栈帧的底部。
bp/ebp/rbp 栈基址寄存器—指向栈底
在8086CPU中,只有bx,si,di,bp这4个寄存器可以用来进行内存单元的寻址
这4个寄存器可以单个出现或只能以四种组合出现;bx和si,bx和di,bp和si,bp和di
bx和bp不能同时出现,si和di不能同时出现
接着是SP,堆叠指标暂存器,其内存放着一个指针,该指针永远指向系统栈最上面一个栈帧的栈顶。SP的作用就是指示当前要出栈或入栈的数据,并在操作执行后自动递增或递减。
sp/esp/rsp(16bit/32bit/64bit)栈寄存器—指向栈顶
段寄存器(特殊寄存器)
段寄存器就是提供段地址的
CS——代码段寄存器(Code Segment Register),其值为代码段的段值
DS——数据段寄存器(Data Segment Register),其值为数据段的段值
ES——附加段寄存器(Extra Segment Register),其值为附加数据段的段值
SS——堆栈段寄存器(Stack Segment Register),其值为堆栈段的段值
FS——附加段寄存器(Extra Segment Register),其值为附加数据段的段值
GS——附加段寄存器(Extra Segment Register),其值为附加数据段的段值
指令指针寄存器:IP
CS和IP,两个最关键的寄存器,他们指示了cpu当前要读取指令的地方
修改CS、IP的指令不同于修改通用的寄存器值的指令,修改通用寄存器的值可以用mov 指令(mav ax,123),mov指令被称为传送指令。而修改CS、IP的指令是jmp指令。jmp指令也被称为转移指令(在X86上不能直接给IP赋值)
ip/eip/rip 程序指令寄存器—指向下一条待执行指令
标志寄存器(特殊寄存器)
进位标志位(Carry Flag && CF):当无符号数的计算结果超出其范围时,CF被置为1, 否则CF被置为0。
溢出标志位(Overflow Flag && OV):当有符号数的计算结果超出其范围时,OV被置为1,否则OV被置为0。
符号标志位(Sign Flag && SF):算术或逻辑操作产生负结果时,SF被置为1,否则SF被置为0。
零标志位(Zero Flag && ZF):算数或逻辑结果产生的结果为零时,ZF被置为1,否则ZF被置为0。
辅助进位标志位(Auxiliary Carry Flag && AC):运算时若最低的四位产生了进位,那么AC被置为1,否则AC被置为0。
奇偶校验标志位(Parity Flag):目标操作数最低有效字节中的1的个数为偶数时,PF被置为1,否则PF被置为0。
常用的汇编指令
汇编语言发展至今,有以下3类指令组成:
1.汇编指令 机器码的助记符,有对应的机器码
2.伪指令 没有对应的机器码,由编译器执行,计算机不执行
3.其他符号 如+,-,*,/等,由编译器识别,没有对应的机器码
不区分大小写,比如
mov和MOV是一样的
简单算术指令
算数运算类指令包括加减乘除、比较与调整指令
ADD: 加法 SUB: 减法
ADC: 带进位加法 SBB: 带借位减法
MUL: 乘法 DIV: 除法
MUL和DIV结果回送AH和AL(字节运算),或DX和AX(字运算)
INC: 加 1 DEC: 减 1
AAA: 加法的ASCII码调整 AAS: 减法的ASCII码调整
AAM: 乘法的ASCII码调整 AAD: 除法的ASCII码]调整
NEG:去补 (对操作数取补(相反数))
CMP: 比较(两个操作数作减法,仅修改标志位,不回送结果)
输入输出端口传送指令
IN I/O端口输入 (IN 累加器, {端口号│DX} )
OUT I/O端口输出 ( OUT {端口号│DX},累加器 )
输入输出端口由立即方式指定时, 其范围是 0-255; 由寄存器 DX 指定时,其范围是 0-65535
逻辑运算指令
逻辑运算类指令分为逻辑运算指令和移位指令两大类
运算指令:
AND: 与运算 OR: 或运算
XOR: 异或运算 NOT: 取反。
TEST: 测试 (两操作数作与运算,仅修改标志位,不回送结果)
移位指令:
SHL: 逻辑左移。 SAL: 算术左移。(=SHL)
RCL: 通过进位的循环左移 RCR: 通过进位的循环右移
程序转移指令
控制转移类指令包括无条件转移指令、条件转移指令、循环控制指令、中断指令、子程序调用和返回指令
无条件转移指令:
JMP: 无条件转移指令
CALL: 过程调用 RET/RETF: 过程返回
中断指令:
INT: 中断指令 INTO: 溢出中断 IRET: 中断返回
内存访问指令&内存读取指令
(当ldr后面没有=号时为内存读取指令)
数据传送指令
PUSH:把字压入堆栈 进栈指令 把16位数据src压入堆栈
POP:把字弹出堆栈 出栈指令 从堆栈弹出16位数据至dst
MOV:传送字或传送字节
MOVSX:先符号扩展,再传送 MOVZX:先零扩展,再传送
目的地址传送指令
LEA:装入有效地址
LDS:传送目标指针,把指针内容装入DS LES:传送目标指针,把指针内容装入ES
LFS:传送目标指针,把指针内容装入FS LGS:传送目标指针,把指针内容装入GS
LSS:传送目标指针,把指针内容装入SS
标志传送指令
LAHF:标志寄存器传送,把标志装入AH
SAHF:标志寄存器传送,把AH内容装入标志寄存器
PUSHF:标志入栈 POPF:标志出栈
程序转移指令
JMP:无条件转移指令
CALL:过程调用 RET/RETF:过程返回
伪指令
DW 定义字(2字节) PROC 定义过程 SEGMENT 定义段
ASSUME 建立段寄存器寻址
ENDS 段结束 END 程序结束 ENDP 过程结束
GCC编译保护机制以及编译命令
科普向但是大多自己看不懂@_@
Linux操作系统中gcc相关的安全保护机制有:1.栈Canaries保护、2.PIE机制、3.NX、4.fortity、relro机制。
checksec 文件 (gdb里peda插件里自带的checksec功能)
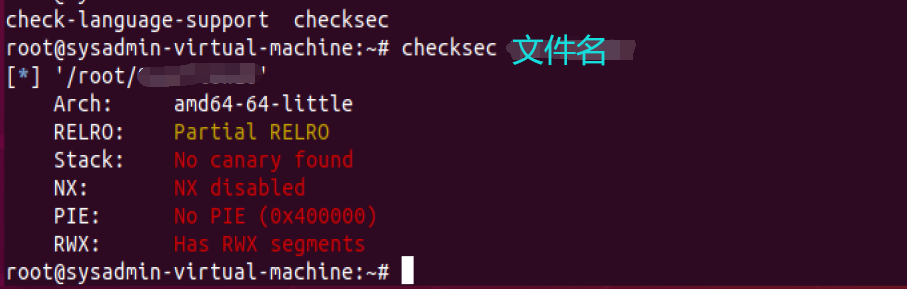
然后就是对这些机制进行简单了解
Arch,xx位的程序,图中为x64
RELRO
Relocation Read-Only (RELRO) 让加载器将重定位表中加载时解析的符号标记为只读,这减少了GOT覆写攻击的面积。此项技术主要针对 GOT 改写的攻击方式。它分为两种,Partial RELRO 和 Full RELRO。
部分RELRO 易受到攻击,例如攻击者可以atoi.got为system.plt,进而输入/bin/sh\x00获得shell
完全RELRO 使整个 GOT 只读,从而无法被覆盖,但这样会大大增加程序的启动时间,因为程序在启动之前需要解析所有的符号。
1 | gcc -o test test.c // 默认情况下,是Partial RELRO |
(此时的我并不懂GOT是啥玩意儿……)
如果开启了FULL RELRO,那么我们是无法修改got表的
Stack-canary
栈溢出保护是一种缓冲区溢出攻击缓解手段,当函数存在缓冲区溢出攻击漏洞时,攻击者可以覆盖栈上的返回地址来让shellcode能够得到执行。当启用栈保护后,函数开始执行的时候会先往栈里插入类似cookie的信息,当函数真正返回的时候会验证cookie信息是否合法,如果不合法就停止程序运行。攻击者在覆盖返回地址的时候往往也会将cookie信息给覆盖掉,导致栈保护检查失败而阻止shellcode的执行。
cookie信息在Linux中被称为canary
通过验证cookie,来判断执行的代码是不是恶意代码。嗯,应该是这个意思
如果该项保护被打开那么无法直接覆盖EIP让程序任意跳转,因为在跳转后将会进行cookie校验(可绕过)
1 | gcc -o test test.c // 默认情况下,不开启Canary保护 |
NX
即No-eXecute(不可执行)的意思,NX(DEP)的基本原理是将数据所在内存页标识为不可执行,当程序溢出成功转入shellcode时,程序会尝试在数据页面上执行指令,此时CPU就会抛出异常,而不是去执行恶意指令。
作用:栈上的数据没有执行权限,防止栈溢出+ 跳到栈上执行shellcode
gcc编译器默认开启了NX选项
1 | gcc -o test test.c // 默认情况下,开启NX保护 |
PIE(ASLR)
该项表示地址随机化保护,如果开启了该项那么程序每次运行的地址都会变化,如果未开启那么No PIE(0x8048000)括号内的代表程序基址
内存地址随机化机制(address space layout randomization),有以下三种情况
1 | 0 - 表示关闭进程地址空间随机化。 |
作用:代码部分地址无关,防止构造ROP链进行攻击
简单使用pwntools
神库,学起来
pwntools是一个CTF框架和漏洞利用开发库,用Python开发,旨在让使用者简单快速的编写exploit。
导入pwntools包
1 | from pwn import * |
context是pwntools用来设置环境的功能。一些二进制文件的情况不同,设置环境来正常运行exp,例如一些时候需要进行汇编,32位汇编和64位汇编不同,若不设置context可能会导致一些问题
os是设置系统 arch是设置架构 debug是设置日志记录级别,方便出现问题的时候排查错误。设置后,通过管道发送和接收的数据都会被打印在屏幕上
1 | context(os='linux', arch='amd64', log_level='debug') |
生成shellcode
1 | shellcode = asm(shellcraft.sh()) |
通过ip和端口号链接
1 | # 第一种连接方式,通过ip和port去连接 |
pwntools提供的有打包函数
1 | p32/p64: 打包一个整数,分别打包为32位或64位 |
打包的时候要指定程序是32位还是64位的,他们之间打包后的长度是不同的。
建立连接后就可以发送和接收数据了
1 | conn.send(data) #发送数据 |
汇编与反汇编
1 | >>> asm('mov eax, 0') #汇编 |
简单使用IDA
神器,学起来^_^
暂且贴几个会看的链接,以后自己用了在慢慢整理
IDA的简单使用
https://www.cnblogs.com/connerlink/p/15639752.html
通过一个例子来介绍IDA的简单使用
https://blog.csdn.net/Casuall/article/details/100191563
简单使用pwngdb
妈的,不是为了打比赛我哪会知道gdb是啥玩意儿啊
亲民的用法介绍不多,B站有个小姐姐的视频私以为很不错,不过不是pwngdb
这里写命令+用法,会慢慢更新
启动gdb,终端输入gdb即可
pwngdb启动后,要先使用file或exec-file命令指出要运行的程序,不然会报错
热知识:gdb中也是可以使用Tab键的
1 | run 文件名 #运行文件(或 r 文件名) |
n 是一个正整数,表示显示内存的长度,也就是说从当前地址向后显示几个地址的内容。
f 表示显示的格式,参见上面。如果地址所指的是字符串,那么格式可以是s,如果地十是指令地址,那么格式可以是i。
u 表示从当前地址往后请求的字节数,如果不指定的话,GDB默认是4个bytes。u参数可以用下面的字符来代替,b表示单字节,h表示双字节,w表示四字 节,g表示八字节。
n/f/u三个参数可以一起使用
【以后可能在这里或者另开一个笔记写使用,目前只是简单整理】
栈溢出
栈(stack)
对于二进制安全,栈结构是最基本要了解的东西
【栈】作为偏旁为木的左右结构的汉字,理解起来并不难。意思大概可以概括为客栈、通道、木制品这三样。在计算机术语中的栈,就是指数据暂时存储的地方。
既然是数据暂时存储的地方自然而然的就有进栈、出栈的说法了——栈,一种先进后出的数据结构
栈是一段连续的内存单元,也就是一段连续的内存地址。
栈就是一个桶,后放进去的先拿出来,它下面本来有的东西要等它出来之后才能出来(先进后出Last In First Out)
堆栈本身就是栈,只是换了个抽象的名字。
栈(操作系统):由操作系统自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。
堆(操作系统): 一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收,分配方式倒是类似于链表。
从内存角度看:
入栈: push 将16位寄存器或者内存中的字型数据 —–>栈顶标记的上面
出栈: pop 将栈顶标记所标识的字型数据 —–> 16位寄存器或内存中
在8086cpu中,在任意时刻,将段地址寄存器ss和偏移地址寄存器sp所组合出来的内存地址当做栈顶标记。
栈的作用
1.栈可以临时性保存数据 2. 可以交换数据
在内存中,在内存10000H~1000FH处分配了16个单元的栈空间。然鹅系统并不会把他当做栈使用
这时候就需要用到寄存器SS、SP(堆栈和指针)了
当寄存器SS、SP所指向的地址就会被当做栈使用
关于SS和SP如何寻址
8086CPU中提供两个16位的地址,一个是段地址,用来指向一个段空间(最大空间为64KB),另一个是偏移地址
物理地址=段地址x16+偏移地址
溢出(Overflow)
【溢出】这个词语的解释是充满某个容器并向外流出。作为一种被黑客利用的漏洞,它的解释是:开发的程序,加上一些精心构造的参数运行后,可以得到电脑的管理员权限,你在你自己电脑上能够做的事情,黑客也做到,等于你的电脑就是他的了。溢出是程序设计者设计时的不足所带来的错误。
溢出的原因
现实状况
在几乎所有计算机语言中,不管是新的语言还是旧的语言,使缓冲区溢出的任何尝试通常都会被该语言本身自动检测并阻止(比如通过引发一个异常或根据需要给缓冲区添加更多空间)。但是有两种语言不是这样:C 和 C++ 语言。C 和 C++ 语言通常只是让额外的数据乱写到其余内存的任何位置,而这种情况可能被利用从而导致恐怖的结果。更糟糕的是,用 C 和 C++ 编写正确的代码来始终如一地处理缓冲区溢出则更为困难;很容易就会意外地导致缓冲区溢出。除了 C 和 C++ 使用得 非常广泛外,上述这些可能都是不相关的事实;例如,Red Hat Linux 7.1 中 86% 的代码行都是用 C 或 C ++ 编写的。因此,大量的代码对这个问题都是脆弱的,因为实现语言无法保护代码避免这个问题。
客观原因
在 C 和 C++ 语言本身中,这个问题是不容易解决的。该问题基于 C 语言的根本设计决定(特别是 C 语言中指针和数组的处理方式)。由于 C++ 是最兼容的 C 语言超集,它也具有相同的问题。存在一些能防止这个问题的 C/C++ 兼容版本,但是它们存在极其严重的性能问题。而且一旦改变 C 语言来防止这个问题,它就不再是 C 语言了。许多语言(比如 Java 和 C#)在语法上类似 C,但它们实际上是不同的语言,将现有 C 或 C++ 程序改为使用那些语言是一项艰巨的任务。
普遍因素
然而,其他语言的用户也不应该沾沾自喜。有些语言存在允许缓冲区溢出发生的“转义”子句。Ada 一般会检测和防止缓冲区溢出(即针对这样的尝试引发一个异常),但是不同的程序可能会禁用这个特性。C# 一般会检测和防止缓冲区溢出,但是它允许程序员将某些例程定义为“不安全的”,而这样的代码 可能 会导致缓冲区溢出。因此如果您使用那些转义机制,就需要使用 C/C++ 程序所必须使用的相同种类的保护机制。许多语言都是用 C 语言来实现的(至少部分是用 C 语言来实现的 ),并且用任何语言编写的所有程序本质上都依赖用 C 或 C++ 编写的库。因此,所有程序都会继承那些问题,所以了解这些问题是很重要的。
溢出原因
数据类型超过了计算机字长的界限就会出现数据溢出的情况。导致内存溢出问题的原因有很多,比如:
(1) 使用非类型安全(non-type-safe)的语言如 C/C++ 等。
(2) 以不可靠的方式存取或者复制内存缓冲区。
(3)编译器设置的内存缓冲区太靠近关键数据结构。
因素分析
1.内存溢出问题是 C 语言或者 C++ 语言所固有的缺陷,它们既不检查数组边界,又不检查类型可靠性(type-safety)。众所周知,用 C/C++ 语言开发的程序由于目标代码非常接近机器内核,因而能够直接访问内存和寄存器,这种特性大大提升了 C/C++ 语言代码的性能。只要合理编码,C/C++应用程序在执行效率上必然优于其它高级语言。然而,C/C++ 语言导致内存溢出问题的可能性也要大许多。其他语言也存在内存溢出问题,但它往往不是程序员的失误,而是应用程序的运行时环境出错所致。
2.当应用程序读取用户(也可能是恶意攻击者)数据,试图复制到应用程序开辟的内存缓冲区中,却无法保证缓冲区的空间足够时,内存缓冲区就可能会溢出。想一想,如果你向200ml的玻璃杯中倒入 250ml 的水,那么多出来 50ml的水怎么办?当然会漫到玻璃杯外面了
3.最重要的是,C/C++编译器开辟的内存缓冲区常常邻近重要的数据结构。假设某个函数的堆栈紧接在在内存缓冲区后面时,其中保存的函数返回地址就会与内存缓冲区相邻。此时,恶意攻击者就可以向内存缓冲区复制大量数据,从而使得内存缓冲区溢出并覆盖原先保存于堆栈中的函数返回地址。这样,函数的返回地址就被攻击者换成了他指定的数值;一旦函数调用完毕,就会继续执行“函数返回地址”处的代码。非但如此,C++ 的某些其它数据结构,比如 v-table 、例外事件处理程序、函数指针等,也可能受到类似的攻击。
栈为什么会溢出
对每个程序来说,栈能使用的内存是有限的,一般是 1M~8M,这在编译时就已经决定了,程序运行期间不能再改变。如果程序使用的栈内存超出最大值,就会发生栈溢出(Stack Overflow)错误,程序就崩溃了。
这个就像木桶里的水,木桶的容量有限,水满了自然会溢出来。
栈溢出
栈溢出指的是程序向栈中某个变量中写入的字节数超过了这个变量本身所申请的字节数,因而导致与其相邻的栈中的变量的值被改变。这种问题是一种特定的缓冲区溢出漏洞,类似的还有堆溢出,bss 段溢出等溢出方式。栈溢出漏洞轻则可以使程序崩溃,重则可以使攻击者控制程序执行流程。此外,我们也不难发现,发生栈溢出的基本前提是
- 程序必须向栈上写入数据。
- 写入的数据大小没有被良好地控制。
pwn手法有很多,包括:
修改返回地址,让其指向溢出数据中的一段指令(shellcode)
修改返回地址,让其指向内存中已有的某个函数(return2libc)
修改返回地址,让其指向内存中已有的一段指令(ROP)
修改某个被调用函数的地址,让其指向另一个函数(hijack GOT)
【这里空一些示例,还在摸索ing】
引用资料出处
如何通俗地解释什么是寄存器?https://www.zhihu.com/question/20539463
汇编常用指令 https://ai-exception.blog.csdn.net/article/details/82950848
8086汇编指令笔记 https://blog.csdn.net/qq_32651225/article/details/53928654?spm=1001.2014.3001.5502
汇编入门 https://blog.csdn.net/qq_27803491/article/details/123026031
汇编语言学习笔记(【汇编语言】小甲鱼零基础汇编) https://blog.csdn.net/inv1796915552/article/details/109559495
linux漏洞缓解机制介绍 https://bbs.pediy.com/thread-226696.htm
gdb使用总结 https://www.cnblogs.com/cxz2009/archive/2011/08/31/2160855.html
Linux GDB使用总结 https://blog.csdn.net/Utotao/article/details/91354704
实例—使用gcc编译器 https://wenku.baidu.com/view/75b45b57cc17552707220898
溢出(计算机程序) https://baike.baidu.com/item/%E6%BA%A2%E5%87%BA/1775951?fr=aladdin
利用汇编详解栈结构 https://www.cnblogs.com/wh4am1/p/6818892.html
CTF Wiki https://ctf-wiki.org/pwn/linux/user-mode/stackoverflow/x86/stackoverflow-basic/
安全总结—-栈溢出(一) https://bbs.pediy.com/thread-185767.htm